


Our world is awash with data. An estimated 32 zettabytes were created last year and we’re expecting over 100 zettabytes to be created in 2023.[1] This pace won’t slow down. On the contrary. The rise of streaming data that will be created by machines, Internet of Things (IoT) and the proliferation of video content, surveillance and smart cities will accelerate as we enter into the zettabyte age, and it requires us to rethink how we store this data.
At Flash Memory Summit 2019, my colleague, Chris Bergey, senior vice president of devices, and I spoke about some of the biggest challenges we face amid this exponential data growth and the foundational technologies needed to help organizations contend with the demands of the zettabyte age.
Golden Bits
One of the essential challenges we’re facing is that as more data is being generated, less of it is being stored. By 2023, only 12 ZB – around 12 percent of data created – will actually be stored.[2] Yet our ability to store data is vital to its potential – utilizing it for analysis, mining, intelligence and value creation.
In order to enable us to get value out of this growing amount of data, we need to figure out how to scale technologies to deliver higher density storage with better cost and power efficiencies.
Scaling to Survive in the Zettabyte Age
As we look at storage technologies in the zettabyte age, and how data will be stored over the next few years, there two key technologies scaling with the demands of data – capacity hard drives and data center SSDs.
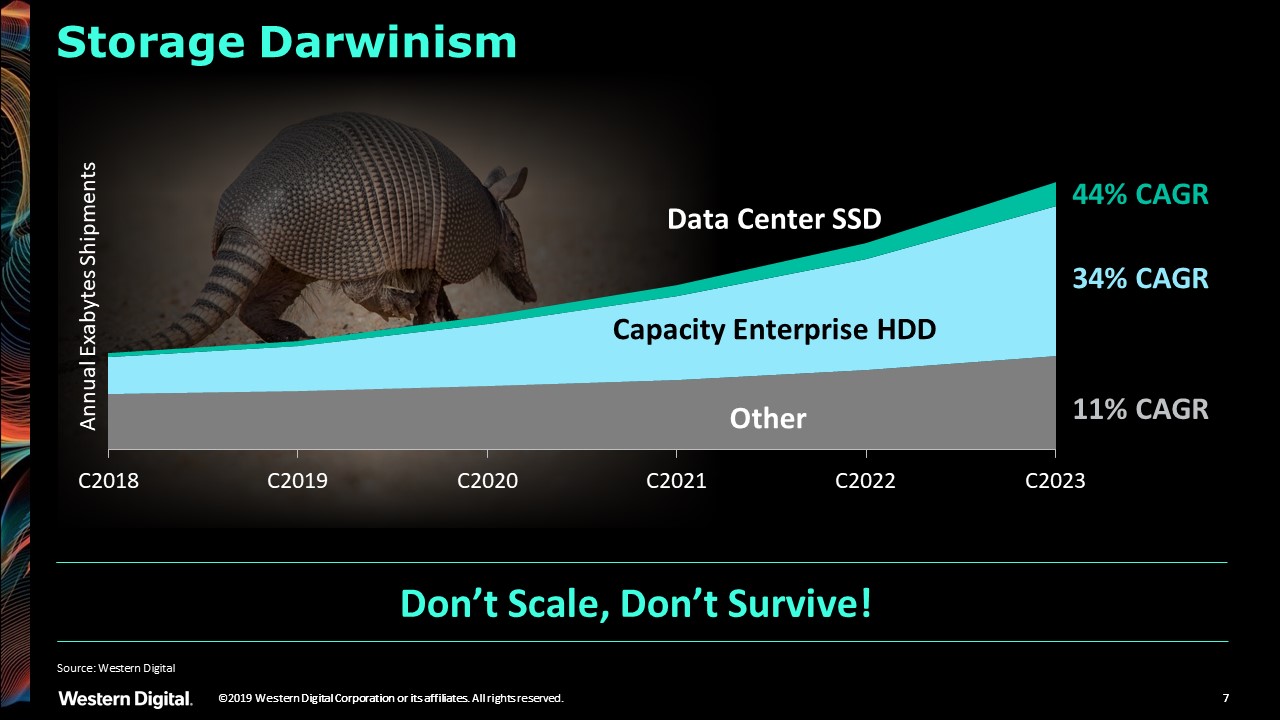
We don’t hear much about hard drives in the age of flash, GPUs and emerging technologies such as AI and machine learning. Yet as you can see in the chart below, not only are capacity hard drives scaling very fast, they also continue to be the mainstay of data center storage capacity. While SSDs are growing even faster in their adoption rate, they are starting from a low installed base and will correspondingly take longer before they store the majority of the data.
Intelligent Data Placement – Taking Learnings from HDDs to SSDs
In our industry, we often place hard drives and SSDs in opposing categories as technologies with very different use cases. However, these two technologies are actually very synergistic. As a company who is leading these two technology pillars, we live this synergy; we’re able to take an idea from one technology and implement it into the other.
Let me explain what this means in the context of scaling for demands in the zettabyte age.
One of the key technologies enabling today’s highest capacity hard drives is “shingled magnetic recording” or SMR. SMR is patterned much like the shingles on a roof. By overlaying tracks on a disk, more data can be squeezed onto the same space – increasing areal density by up to 20 percent compared to conventional recording.
It took some time for this concept to catch on as data must be written sequentially to the drive. This step can not only can impact performance but more importantly, it requires some rearchitecting at the host-level. Yet by working with the industry on developing open standards and tools to support SMR adoption processes, host-managed SMR is seeing rapid adoption. That’s because the heavy lift on the host end is well worth the outcome and benefits. In fact, we expect that fifty percent of our data center HDD exabytes shipped will be on SMR drives by 2023.
Now, we are taking the same basic concept of intelligent data placement from SMR for HDDs to our next-generation SSDs.
Scaling NAND is More Than Just Layers
If we look at SSDs, scaling capacity and cost is dependent on very different design elements than HDDs. These include die size, page size, power, total bits per cell, and total number of planes. Today, we have 96-layer 3D NAND as the standard. By calendar year 2020, we expect to roll out BiCS5 with over 100-layer 3D NAND. This scaling, however, is linear and cost-prohibitive if done in isolation. Put simply, more layers would cost more money.
So, at the same time that we are building up, we are also building out. This means we are leveraging breakthroughs to shrink the size of memory holes while logically growing the number of bits per cell.
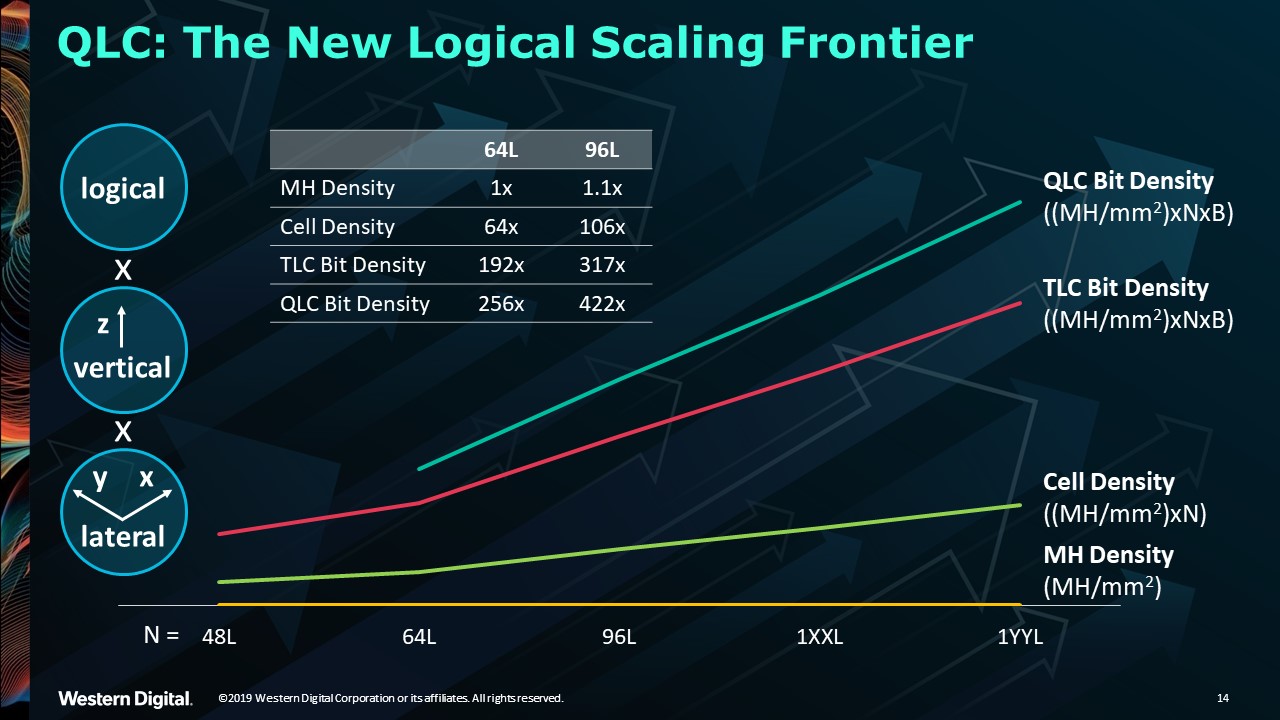
Yet these advances come at a price as things get more complicated. For example, to maintain the same write bandwidth using more bits per cell, the page size would need to be increased. In turn, a larger page size would potentially create larger dies and use more power.
As in life, everything is linked together – for better or for worse. So, with the number of bits per cell increasing, we inevitably see a write degradation. This in turn means that our ability to scale data center SSDs to higher capacities and lower costs will also depend on additional technologies coming into play.
Zoned Namespaces – Lean, Intelligent SSDs
This is where we brought the lessons learned from SMR technology and applied our technical expertise in SSDs. Zoned namespaces is an architectural approach that divides flash media into zones. These zones can only be written sequentially, much like data written sequentially to tracks on SMR HDDs.
Why is this beneficial for SSDs? When SSDs were initially introduced, they implemented an internal management system called Flash Translation Layer (FTL) that helped manage how data is written to the device. This allowed SSDs to operate seamlessly in data center environments. By modifying the FTL to allow the host to manipulate the data, we can move the intelligent data placement from the device to the host, using these sequential zones much like host-managed SMR. This allows us to build flash devices with very significant benefits:

The end result will be SSDs that deliver better density, are far more cost efficient and incredibly lean.
Thinking Beyond the Drive
Our learnings in SMR showed us that we have to think beyond the drive to take into consideration the entire stack as well as new compute aspects of virtual machines, containers, multitenant clouds, serialized sensor workloads and tremendous amount of video.
By leveraging a data intelligence and collaboration layer we can help serialize incoming and streaming data to take advantage of purpose-built zoned storage devices. These devices can dramatically reduce TCO and improve read-intensive performance, and they open up unique opportunities for next-generation features based on concepts of VMs, multi-tenancy, and server-less functions.

In both SMR and QLC zoned-namespaces SSDs, the devices are no doubt the underlying workhorse. Yet what intelligent data placement does is support this work outside the drive to augment what is happening inside it. As we move towards purpose-built architectures, all the pieces will have to work together in the most efficient and optimized manner.
Doing the “Write” Way, the Right Way
As new architectures look to zoned storage solutions, I am proud to say that we approached this concept the right way: through an open-source, standards-based platform. We’ve been working with the community to establish zoned namespaces (ZNS) as an open standard that can use the same interface and API as SMR. This important step allows data centers to adopt a single interface that can communicate with the entire storage layer regardless of the environment they choose.
We’ve launched ZonedStorage.io as a hub for developers to find all the open source documents, tools and best practices needed to adopt SMR and Zoned Namespace technologies and we have taken it upon ourselves to maintain and track the Linux® kernel work with the open source community to support these initiatives.
Hopefully, you are as excited as I am about where data infrastructure is heading in the zettabyte age. I invite you to follow the links below to learn more:
● Visit ZonedStorage.io for developers, code, documents, and tools
● Learn more about Zoned Storage and the Zoned Storage Initiative
● Find SMR HDDs for high-capacity enterprise data storage
● See the Ultrastar® DC SN340 NVMe™ SSDs – our first SSD leveraging a lean architecture

Forward-Looking Statements
Certain blog and other posts on this website may contain forward-looking statements, including statements relating to expectations for our product portfolio, the market for our products, product development efforts, and the capacities, capabilities and applications of our products. These forward-looking statements are subject to risks and uncertainties that could cause actual results to differ materially from those expressed in the forward-looking statements, including development challenges or delays, supply chain and logistics issues, changes in markets, demand, global economic conditions and other risks and uncertainties listed in Western Digital Corporation’s most recent quarterly and annual reports filed with the Securities and Exchange Commission, to which your attention is directed. Readers are cautioned not to place undue reliance on these forward-looking statements and we undertake no obligation to update these forward-looking statements to reflect subsequent events or circumstances.
[1] IDC Global DataSphere Forecast, 2019-2023: Consumer Dependence on the Enterprise Widening, January 2019, DOC #US44615319 [2] IDC, Worldwide Global StorageSphere Installed Base Forecast, 2019–2023: The Global StorageSphere Installed Base by Core, Edge, and Endpoint, April, 2019, DOC #US45009319