


NVM Express (NVMe™) is the first storage protocol designed to take advantage of modern high-performance storage media. The protocol offers a parallel and scalable interface designed to reduce latencies and increase IOPS and bandwidth thanks to its ability to support more than 64K queues and 64K commands/queue (among other features and architectural advantages). But what exactly does this mean and why are NVMe queues so important?
In this blog, I will explain NVMe queues, their advantages and how higher number of queues are leveraged in the next generation server, storage systems and application architectures. For those of you, who are new to NVMe, I’ve also written a short technical guide on what is NVMe and why it matters for your business.
NVMe Queues – the IO Path
On the IO path, NVMe offers at least one submission and one completion queue per core without any conflicts or locks, NUMA aware. In addition to IO queues, NVMe also supports administrative queues for non IO operations. As a rule of thumb, the number of queues is a function of the complexity of the expected workload and the number of cores in a system.
The IO Path: the host writes a fixed size circular buffer space, a submission queue, either at the host or drive memory and triggers the doorbell register when commands are ready to execute. The controller then picks up the queue entries in the order received, or in the order of priority. The completion queues post the status for completed commands. Multiple submission queues can have a single completion queue; see Fig. 1 below. This allows the CPU to identify completed commands, free up hardware resources, and enable command execution optimization such as out of order execution with well-defined arbitration mechanisms.

Application Processes and Storage Architecture
To understand IO queues, let us first establish some interface baselines. Both SATA and SAS interfaces support a single queue with 32 and 256 commands respectively, limited for capacity and performance scaling. On the other hand, NVMe offers more with 64K queues and 64K commands per queue. That’s a difference of a staggering magnitude.
However, what do these queues have to do with servers, storage systems as well as applications? For this we have to examine new microservices architecture and system designs using message queues.
In the current generation of distributed computing, where applications run on different compute nodes, the architecture enables applications to split processes into smaller and interconnected service modules, or microservices, instead of one big monolithic application. As my colleague recently explained: “The concept of microservices is that rather than building and maintaining complex applications, an easier, more flexible and robust approach is to break applications into smaller, composable components that can work together. Basically, these are single-function modules that are well-defined and distinct, and together they make up a complex software application.” The microservices architecture eases application development, deployment, maintenance and allow them to run mutually independently.

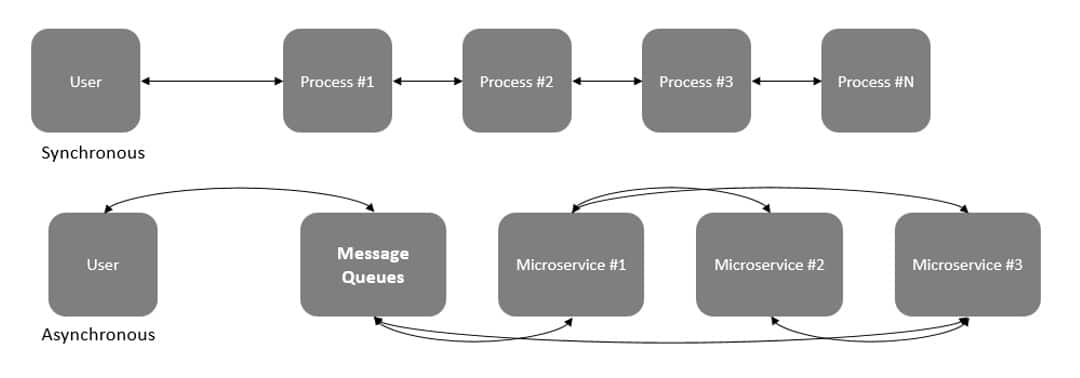
Let’s use an e-commerce application as an example. E-commerce applications run everything from product display and catalog, user authentication, cart management, purchase and payment, tracking and delivery synchronously as some of its key processes. All underlying processes respond to changes/ events simultaneously, synchronously, whether needed or not. However, using a distributed architecture, e-commerce applications can have a frame with several granular microservices running asynchronously – e.g. authentication microservice, purchase and payment microservice, delivery microservice and so on.
In this construct, we can see that not all the microservices need to run synchronously; they can exchange and process data when they need to i.e. asynchronous mode (e.g. event triggered processing) but that requires buffer space to hold data at some intermediate stage, message queues. The message queue is one such way to allow various microservices to exchange and process application data asynchronously and hence improve performance, reliability, and scalability; see Fig. 2.
NVMe Queues – Speeding Up Applications
Now that we have understood microservices and message queues, let us go back to NVMe IO queues and their use cases. The compute nodes, which own the overall applications as well as underlying microservices, exchange data asynchronously with each other through message queues and perform IO operations with their respective storage devices. To speed up the applications, microservices have to exchange and process data faster, which means that the systems somehow need to queue up and process as many IO requests as possible. With longer NVMe IO queues, the storage devices can queue IOs and fully utilize all available parallel channels to access underlying storage media and complete IOs as fast as possible.
Since the NVMe protocol supports out of order processing (recall native or target command queueing in SATA/ SAS protocols), the storage devices can re-order IOs and further improve IO performance. As I mentioned above, both SATA & SAS SSDs support single queue with 32 and 256 commands respectively while NVMe SSDs, support 64K queues and every queue can go up to 64K commands. A remarkable jump that allows NVMe devices to serve longer IO queues and process them faster. Also, system or applications then require fewer drives to complete the same tasks in comparison to SATA or SAS SSDs, a great cost efficiency and benefit.
NVMe Queues and Their Impact on Flash Storage Systems

Looking at all-flash storage systems, the length of available drive IO queues limit the length of storage controller (HBAs/ Expanders etc.) message queues and therefore limit system performance and scalability. Compared to SATA and SAS SSDs, NVMe drives offer longer queues as well as more commands/queue supporting faster and higher number of IO operations/ drive. This helps storage controllers to transfer more commands to the drive and do more IOs, hence improving overall system performance and scalability. In addition, systems/ applications will then need fewer drives resulting into lower power as well as cooling requirements i.e. a TCO as well as TCA benefits.
NVMe and Next Generation Workloads
Because of lower performance conventional storage media, CPUs were designed to wait for data, which kept them starving and wasted many (expensive) processing cycles. With PCIe and solid state media- NAND, SSDs created parallel data paths to underlying storage bits, which feed CPUs at speed and enable them to process data and not wait anymore. When compared with SATA or SAS SSDs, PCIe or NVMe SSDs reduced overall software stack to fetch and bring data back to CPU.
With IO queues, systems can shift more commands to drive queues and then drives can group them or process them out of turn. Resulting into higher performance, lower latencies, and more scalability. Net/ net, all this reduces CPU cycles and enables them to run other services such as compression, encryption etc. The next generation CPUs offering increasing number of PCIe lanes, which will allow higher number of drives to connect and therefore more performance and capacity scale up possibilities.
Next generation, data-driven applications are likely to run higher number of performance and compute intensive workloads that applications we are accustomed to today. The system architecture will heavily rely on microservices and message queues to make them more scalable with even fewer hardware resources. With longer queues, the storage devices can process and complete IO requests even faster resulting into fewer drives, do more with less hardware, lower data center footprint, and increase return on investment (ROI). As we look into architectures to support the overwhelming data demands of the Zettabyte Age, NVMe will play a key role in enabling efficient, data-optimized architectures.
Learn More
• Learn about our latest NVMe SSDs
• See our NVMe Storage Servers
• Get to know our NVMe all-flash systems