


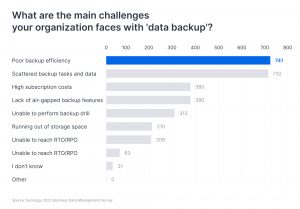
Backup performance is considered one of the most critical elements of data protection. In a survey conducted by Synology that focused on 1,500 IT decision-makers, more than half of the respondents ranked backup speed as one of their primary challenges. Sluggish backups can stall an organization’s production processes. And if a backup task exceeds its designated time frame, it has the potential to linger indefinitely, leaving critical workloads unprotected.
As an essential service safeguarding data stored on Synology systems, Hyper Backup has supported incremental backup mode since its introduction, reducing the time required for backup tasks. Nevertheless, with businesses accumulating data at an exponential pace, the call for faster backups has surged. Recognizing this trend, we re-examined the design of Hyper Backup and introduced a set of enhancements to boost Hyper Backup’s performance in DSM 7.0.
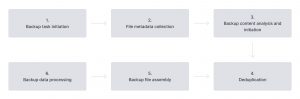
To achieve the goal of accelerating backup speed, we have thoroughly deconstructed Hyper Backup’s task execution process into six steps:
- Backup task initiation
- File metadata collection
- Backup content analysis and initiation
- Deduplication
- Backup file assembly
- Backup data processing
For each step, we utilized tools such as perf, ebpf, and iperf to analyze the on-cpu aspects (e.g., CPU usage, memory) and off-cpu elements (e.g., disk I/O, system call). Our findings concluded that by enhancing two mechanisms, we can significantly boost Hyper Backup performance, especially in scenarios involving massive amounts of data.
Enhanced Parallel Processing
Firstly, we fine-tuned parallel workflows within backup tasks. In each backup service, “providers” generate tasks, while “consumers” execute them. For example, a provider might identify files that need to be backed up, followed by a consumer executing read/write operations. Throughout the backup mission, balanced loading and waiting times for consumers and providers prove pivotal. Factors like task distribution and CPU/memory resource allocation impact this equilibrium.
In fact, balancing task and resource allocation in software development is an ongoing process. After a thorough reevaluation and restructuring, we modularized backup tasks to avoid resource clashes in DSM 7.0. These refinements enable seamless concurrent handling of each backup process segment, mitigating bottlenecks and yielding a notable 30% boost in incremental backup efficiency.
Revamped Metadata Collection Process
Next, we consolidated and streamlined metadata collection. During backups, copious metadata is needed for incremental backups and deduplication. Previously scattered across procedures, these metadata collection processes hampered backup speed. To tackle this, we scrutinized metadata requests in every process, removed redundancies, and simplified the metadata-gathering process.
Moreover, we introduced a memory cache mechanism and centralized metadata retrieval to lift I/O burdens off hard disks. This accelerates incremental backup and deduplication tasks’ speed.
With these enhancements, Hyper Backup’s performance underwent substantial improvement. In our lab testing, using a 10-million-file dataset totaling 18TB, with a 5% file change rate, the new Hyper Backup version demonstrated a remarkable 95% improvement over the previous release. This effect shines notably in scenarios handling over a million files. Hence, we strongly recommend businesses with large amounts of data to upgrade their DSM and Hyper Backup to the latest version.
Moving forward, we will continue exploring how to identify changes in files more quickly and accurately during backup task execution and meet more demanding challenges, such as extreme cases with over a hundred million file changes or unexpected events like abnormal power outages. Optimizing product performance is an ongoing endeavor, and Synology is committed to continuously delivering a better user experience.